

Der Schutz geistigen Eigentums und die Erfindung des Computers
BLOG: Sprachlog

Google Books ist für mich schon lange ein unverzichtbares Werkzeug zur Literaturrecherche, aber jetzt hat Google eine weitere interessante Verwendungsmöglichkeit geschaffen (habe ich eigentlich schon mal erwähnt, dass ich Google liebe?): den Google Books Ngram Viewer.
Der Google Books Ngram Viewer macht es möglich, die Häufigkeitsentwicklung von Wörtern und Phrasen über die letzten zweihundert Jahre zu verfolgen und so eine Vielzahl an kultur- und sprachgeschichtlichen Fragestellungen zu untersuchen. Schöne sprachwissenschaftliche Beispiele finden sich zum Beispiel in Kristin Kopfs Schplock und Michael Manns lexikographieblog).
Aber nicht nur Sprach- und Kulturwissenschaftler/innen — die ähnliche Untersuchungen auch vor Googles neuem Werkzeug schon durchgeführt haben — nutzen den Ngram Viewer für interessante Untersuchungen, sondern auch viele andere Menschen. Markus Dahlem, zum Beispiel, hat in den Brainlogs eine kleine medizin- und kulturgeschichtliche Analyse von Migräne, Epilepsie und Schlaganfall durchgeführt, und Techdirt-Gründer Mike Masnick hat nach den Ausdrücken patents, copyright, trademark und intellectual property gesucht, um einen Eindruck von der Geschichte dieser Begriffe und der dahinterstehenden Ideen zu bekommen. Er bekam folgendes Ergebnis:

Der interessanteste dieser Ausdrücke ist für Masnick intellectual property: Er tritt überhaupt erst seit etwa 1980 auf und steigt dann in seiner Häufigkeit stark an, wird also offensichtlich erst mit dem Aufkommen von Computern und dem Internet gesellschaftlich relevant.
Mich hat interessiert, ob das im deutschen Sprach- und Kulturraum auch so ist, und ob wir den Ausdruck geistiges Eigentum möglicherweise aus der englischsprachigen Welt übernommen haben. Ich habe also zunächst nach den ungefähren deutschen Entsprechungen für Masniks vier Begriffe gesucht:
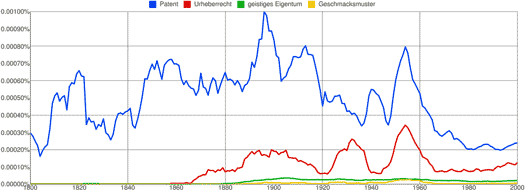
Das Ergebnis hat mich überrascht: Es scheint keinen nennenswerten Anstieg in der Häufigkeit des Ausdrucks geistiges Eigentum zu geben. Allerdings ist er im Vergleich zu Patent und Urheberrecht insgesamt sehr selten, sodass es mir möglich erschien, dass ein Anstieg vielleicht nur wegen der geringen Auflösung unsichtbar sein könnte.
Ich habe deshalb noch einmal einzeln nach geistiges Eigentum gesucht. Diesmal lässt sich ein klarer Anstieg feststellen, allerdings schon viel früher als im Englischen, nämlich zwischen 1880 und 1900 — seitdem ist die Häufigkeit relativ stabil:
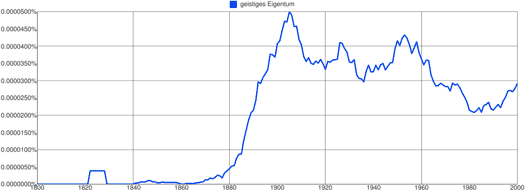
Nun muss man im Deutschen allerdings, anders als im Englischen, die unterschiedlichen Flexionsformen von Adjektiven und Substantiven berücksichtigen. Ich habe deshalb noch einmal nach allen Formen des Begriffs gesucht, also nach geistiges Eigentum, geistige Eigentum, geistigen Eigentum, geistigem Eigentum und geistigen Eigentums:
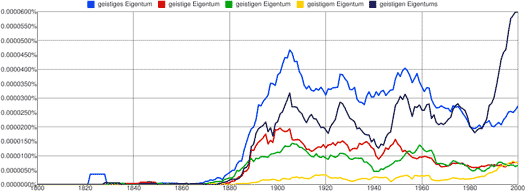
Das Ergebnis ist überraschend. Die Formen verhalten sich alle in etwa gleich, mit einer großen Ausnahme: Der Genitiv geistigen Eigentums steigt ab 1980 stark an, also ab demselben Zeitpunkt, ab dem im Englischen der Ausdruck intellectual property ansteigt. Es stellt sich natürlich die Frage, woran das liegen könnte.
Nominalphrasen im Genitiv modifizieren typischerweise Substantive, und bei „… geistigen Eigentums“ kamen mir intuitiv zwei mögliche Kandidaten für ein solches Substantiv in den Sinn: Diebstahl und Schutz. Eine schnelle Google-Suche ergab, dass dies tatsächlich die zwei häufigsten Substantive sind, die mit dem Genitiv geistigen Eigentums auftreten, und so habe ich im Google Ngram Viewer die Ausdrücke Diebstahl geistigen Eigentums und Schutz geistigen Eigentums gesucht:
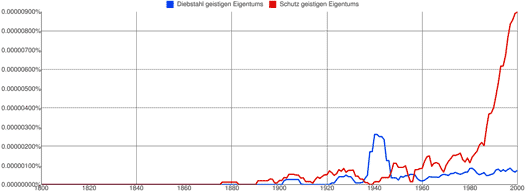
Wie man sieht, ist es der Ausdruck Schutz geistigen Eigentums, der für den starken Anstieg des Genitivs seit 1980 verantwortlich ist.
Die Idee des geistigen Eigentums gibt es im deutschen Sprach- und Kulturraum also schon seit mindestens hundertdreißig Jahren, aber geschützt werden muss dieses Eigentum erst seit eine Technologie existiert, durch die die Gesellschaft insgesamt daran teilhaben könnte. Das ist schade, denn wie das Grundgesetz so schön sagt: „Eigentum verpflichtet. Sein Gebrauch soll zugleich dem Wohle der Allgemeinheit dienen.“
BOHANNON, John (2010) Google Opens Books to New Cultural Studies. Science 17, S. 1600.DOI:10.1126/science.330.6011.1600 [Link (Kurzfassung)]
MASNIK, Mike (2010) The history of intellectual property based on its use in books, Techdirt, 30. Dezember 2010. [Link].
MICHEL, Jean-Baptiste, Yuan Kui SHEN, Aviva PRESSER AIDEN, Adrian VERES, Matthew K. GRAY, William BROCKMAN, The GOOGLE BOOKS TEAM, Joseph P. PICKETT, Dale HOIBERG, Dan CLANCY, Peter NORVIG, Jon ORWANT, Steven PINKER, Martin A. NOWAK, and Erez LIEBERMAN AIDEN (2010) Quantitative Analysis of Culture Using Millions of Digitized Books. Science, DOI: 10.1126/science.1199644. [Link (Kurzfassung)]
© 2010, Anatol Stefanowitsch
Dieser Beitrag steht unter einer Creative-Commons BY-NC-SA-3.0-(Deutschland)-Lizenz.
Pan
Fängt das geistige Eigentum auf deutsch nicht schon ein bisschen früher an? Auf englisch gehts aber scheinbar wirklich erst ab den 80ern los. Komisch.
bis 2008
Wenn man den Zeitraum auf bis 2008 erweitert (habe auch die von Pan erwähnte -Schreibung reingesteckt), werden die Kurven noch krasser … 🙂
Link: http://ngrams.googlelabs.com/…=8&smoothing=3
Google
Was mich im Zusammenhang mit den Suchmaschinen zur Zeit besonders interessiert, ist die Frage, wie weit die Entwicklung mit den Übersetzungen über den Textabgleich bereits vorhandener Übesetzungen im Netz gediehen ist.
Ich las vor einiger Zeit, dass einige Leute daran arbeiten, in naher Zukunft Texte aus so gut wie jeder beliebigen Sprache in eine beliebige andere zu übersetzen, indem sie das Netz nach bereits vorhandenen Übersetzungen durchforsten, nach Sinnhaftigkeit überprüfen und die vermutlich richtige auf diese Weise finden. Mit dieser Methode müsste man sich nicht mehr wie zur Zeit noch mehr oder weniger Wort für Wort durch einen Text und mit immer noch sehr bescheidenen Ergebnissen durchackern, sondern erhielte beste Ergebnisse, zumal die bisherigen Überstzungsprogramme allesamt nicht viel zu taugen scheinen(?) und letztendlich immer wieder an den Grammatiken oder an Sprachfeinheiten scheitern.
Vision der Entwickler soll sein, dass niemand mehr, zum Beispiel Schüler, umständlich und zeitraubend eine oder gar zahlreiche Fremdsprachen lernen muss, nur um fremdsprachliche Publikationen mehr schlecht als recht lesen zu können oder gar in einer Fremdsprache zu publizieren. In ferner Zukunft könnten nach den Vorstellungen jener auch Übersetzer in vielen Fällen überflüssig werden und die Kosten dafür somit entfallen, wenn dieses Programm später nur entsprechend schnell arbeiteten. Bei der Entwicklung deartiger Programme setzt man zur Zeit jedoch nur auf die Schriftform und noch nicht auf die Kommunikation von Menschen untereinander, weil die Umsetzung in die gesprochene Sprache naturgemäß viel schwieriger ist.
Meine Frage ist nun, gibt es hierüber schon neue Erkenntnisse?
@Klausi
Meinst du vielleicht statistische maschinelle Übersetzung? Sie nimmt allerdings nicht bereits übersetzte Texte als Muster, sondern zielsprachliche Texte. (Einen groben Überblick gibt die englische Wikipedia hier: http://en.wikipedia.org/…cal_machine_translation)
Guten Tag,
ich hatte im Rahmen meines Studiums das Glück, den Gastvortrag eines Anwalts (der übrigens u.a. das von Ihnen geliebte Google schon vertrat) einer der großen Kanzleien im europäischen Raum (Wolf Theiss), zu besuchen. Thema dieses Vortrags war des Anwalts Spezialgebiet, “Geistiges Eigentum”. Dieser Name ist allerdings in den drei bis vier Stunden nicht ein einziges Mal gefallen, stattdessen wurde konsequent “Intellectual Property” oder nur “IP” – mit engl. Aussprache – verwendet.
Ist natürlich absolut nicht repräsentativ, soll nur als Anstoß dienen – vielleicht verwendet die Branche hier die englischen Begriffe?
mfg
[Die Häufigkeit von IP im hier relevanten Sinne lässt sich nicht überprüfen, da diese Abkürzung ja auch für „Internet Protocol“ steht. Der Ausdruck intellectual property kommt natürlich auch im deutschen Google-Books-Corpus vor und steigt ab 1980 an, ist aber insgesamt seltener als der deutsche Ausdruck, siehe hier. — A.S.]
Immaterialgüterrecht und Marke
Eine interessante Analyse bietet auch das Ergebnis zum Begriff des Immaterialgüterrechts als ursprüngliche Entsprechung zum Recht des sog. Geistigen Eigentums. Dieser erlebte offenbar schon zwischen beiden Weltkriegen eine gewisse Akzeptanz bzw. Verbreitung.
Übrigens wäre für den Begriff Trademark der der Marke bzw. des Warenzeichens (bis 1994 gebräuchliche Bezeichnung) die treffendere deutsche Entsprechung.
[Ja, Immaterialgut/-güter hat eine interessante Häufigkeitsspitze zwischen 1920 und 1940, ist aber insgesamt schon damals seltener als geistiges Eigentum, siehe hier — A.S.]
Hm, und da sage nochmal jemand, der Genitiv sei eine aussterbende Struktur im Deutschen…
Das geistige Eigentum ist doch eher eine monopolartige Verfügungsgewalt über Handlungen, die von der Staatsgewalt Individuen, Gruppen oder Lobbys zugestanden wird. Im Grund ähnlich der Übertragung von Zolleinkünften, Steuerprivilegen oder Handelsmonopolen also nichts wirklich Neues. Der Bedarf an solchen Sachen besteht einfach deshalb, weil materielle Güter wie Immobilien, Gold oder Unternehmen in der Menge begrenzt sind und damit das natürliche Streben von Investoren und Bankern nach immer mehr Reichtum begrenzen würde.
bis 2008 (2)
Kristin hat imho einen wichtigen Zusammenhang dargestellt – die ganze Urheberrechtsdiskussion ist schließlich vor allem seit dem Aufkommen der Tauschbörsen und dem damit verbundenen (auch selbstverschuldeten) Niedergang der Musikindustrie richtig ins Rollen gekommen. Jedenfalls in meiner subjektiven Wahrnehmung, und wenn man die Kurven bis 2008 verfolgt, dann scheint das genau das zu bestätigen.
Nachtrag 2008
selbiges fand eben erst nach der Jahrtausendwende statt… wenn ich mich recht erinnere ging das so gegen 2001, 2002, 2003 richtig los mit Napster und Konsorten…
Anregung
Eventuell wäre es von Interesse einfach nur das Wort ´Autorenrechte(e)´ zu suchen. Oder ist dieses Wort zu simpel?
[Hier der Vergleich der Wörter Autorenrechte und geistiges Eigentum. — A.S.]
An Kristin
Ja, das muss es gewesen sein. Vielen Dank für den Wink.
Habe darüber nun auch was im Netz gefunden, nachdem ich das richtige Stichwort (statistische Übersetzung) hatte. Ich meine sogar, es ging in dem Bericht, an den ich mich dunkel erinnerte, um Franz Josef Och:
http://www.spiegel.de/…gel/print/d-28591084.html
Hier sogar per “Tube” http://www.youtube.com/watch?v=rThQedY-H4Q
Danke für den Vergleich
Die gegen Ende hin deutlich negativ verlaufende Korrelation von Autorenrechte und geistigem Eigentum ist interessant.
Dies deutet darauf hin, dass es statt Rechtsschutz andere Einflüsse gibt, wieso die Wertigkeit von geistigem Eigentum in letzter Zeit wichtiger ist. Könnte dieser Hebel nicht der erlösbare ´Schadensersatz´ sein, welcher sich bei Prozessen heraus holen lässt?
Manche Werte (Frauen-/Menschenrechte (Diskriminierung), Gesundheit, Moral) haben in den letzten Jahrzehnten nur deshalb eine neue Wertschätzung/Bewertung erhalten, weil sich (speziell in den USA) darauf begründete Schadensersatzforderung ableiten ließen.
Monopolartige Verfügungsgewalt
@ adenosine
Die Analyse der monopolartigen Verfügungsgewalt finde ich durchaus richtig. Man muss allerdings auch bedenken, dass ohne den Schutz geistigen Eigentums eine Publizierung häufig gar nicht stattfände.
Beispielsweise wurden viele Entdeckungen von Seefahrern als Geheimwissen unter der Decke gehalten, um das Wissen alleine auszubeuten. Siehe Wikipedia (Entdecker): “um 1000 nach Chr. entdeckten Wikinger unter der Führung von Leif Eriksson Amerika (Vinland). Das Wissen um diese Entdeckung blieb wohl auf eine kleine Gruppe begrenzt”.
Eigentum verpflichtet
Das funktioniert ja schon beim Geld nicht, wieso sollte es bei geistigem Eigentum klappen?
Hintergrundrecherche
Imho zeigt dieser Beitrag, dass der Ngram-Viewer zwar Daten liefert, aber dass daraus Schlüsse zu ziehen durchaus schwierig ist. Die Idee des geistigen Eigentums ist prinzipiell schon sehr alt, trägt aber den Namen erst seit etwa der Hälfte des 18. Jahrhunderts (also entstand der Begriff vor etwa 250 Jahren). Aber auch schon Autoren wie Martin Luther (Mitte 16. Jh.) empfinden es als Diebstahl, wenn ihre Texte ohne Autorisierung nachgedruckt werden.
Ich empfehle als Einstiegslektüre zum Thema Theisohn, Philipp: “Plagiat. Eine unoriginelle Literaturgeschichte.” Der Text ist flüssig geschrieben und angenehm zu lesen und dabei doch wissenschaftlich fundiert. Theisohn zeigt darin die Entwicklung der Idee des gestohlenen Textes von der griechischen Antike bis zur digitalisierten Gegenwart.
Also dieser Beitrag ist eine nette Spielerei, sollte aber unbedingt auch als solche und nicht als mit der geschichtlichen Entwicklung korrelierend wahrgenommen werden.
Es gibt nur eines wovor die Besitzer geistigen Eigentums noch mehr Angst haben als vor seinem Diebstahl:
Davor, dass es erst gar nicht in Umlauf kommt.
Wer so besorgt um seine geistigen Ergüsse ist, soll sie doch einfach für sich behalten. Sicherer geht es nicht!
Anzahl deutscher Quellen
Interessante und aufschlußreiche Datenabfrage.
Aber wenn ich mich recht entsinne, sind noch nicht wirklich ausreichend deutschsprachige Buchquellen in dieser Datenbank zur Verfügung. Eine wirklich relevante Aussage bräuchte also noch eine Angabe zur quantitativen Umfang der Quellen.
ohne urhr keine publikation?
@14 (wentus):
das ist eine oft gehörte these. gerhard höffner kommt in seinem lesenswerten zweibänder zu anderen schlüssen.
wenn man weiter differenzieren will, als ihre griffige behauptung es erlaubt, lohnt die historische betrachtung der deutschen urheberrechtsgeschichte und der vergleich mit anderen legislaturen sehr.
dazu möchte ich sie ermutigen. es reicht nicht, vor einer althergebrachten weltanschauung recht zu behalten. als publizistisches ökosystem in neuer zeit überleben zu können, hat durchaus seinen charme.
.~.
intellectual property
Im Englischen gibt es den Begriff tatsächlich schon ca. seit den 1860ern. Dort wurde damit, wie heute auch, versucht, Urheberrecht, Patente und Markenrecht unter einen Hut zu bringen und somit für diese wesentlich sehr unterschiedlichen Bereiche einheitliche Restriktionen einzuführen.
Nachzulesen in Adrian Johns’ “Piracy”.
http://www.goodreads.com/book/show/6990457-piracy
Korpusgröße
@Jens Best: Die Gesamtmenge ist für das Deutsche bekannt (37 Milliarden Wörter), nur leider nicht, wie genau die Texte auf die Jahre verteilt sind. (Oder ich habe die entsprechende Angabe nur noch nicht gefunden.)
Für das Gesamtkorpus (alle Sprache) steht im Science-Paper:
Für Wörter, die hochfrequent sind, und bei denen keine Schwankungen erwartbar sind, scheinen mir im Deutschen ab ca. 1770 hinreichende Daten vorzuliegen, d.h. es gibt keine nennenswerten Schwankungen mehr. Hier mein Test: http://ngrams.googlelabs.com/…=8&smoothing=0
Für weniger frequente Wörter kann das natürlich anders aussehen, je früher die Daten, desto weniger zuverlässig, nehme ich an.
Schutz und Diebstahl geistigen Eigentums
Geschützt werden muß geistiges Eigentum erst, seit eine Technologie existiert, die dessen massenhaften Diebstahl bzw. dessen Zweckentfremdung, widerrechtliche Adaption und unautorisierte Verwendung ermöglicht. Dies dient sicherlich nicht dem Wohle der Allgemeinheit, denn es führt über kurz oder lang dazu, daß die Erbringer geistiger Leistungen ebendiese Tätigkeit entweder einstellen oder ihre Erzeugnisse nicht mehr publizieren, da diese Leistungen durch den massenhaften Diebstahl im Internet nicht mehr in angemessener Weise honoriert werden. Die in den letzten Jahren leider in die Mode gekommene Idee, geistige und kulturelle Leistungen seien nicht Eigentum dessen, der sie erbracht hat, sondern müßten der Allgemeinheit gehören, ist letztlich nur eine Fortsetzung des Enteignungswahnes des Sozialismus mit anderen Mitteln auf geistiger Ebene. Und wohin das geführt hat, sollte jedem halbwegs geschichtlich informierten Menschen bekannt sein.
@„Heinrich von Aspelkamp“
Sicher, die Erbringer geistiger Leistungen, bislang fürstlich entlohnt, werden bedroht durch massenhaften Diebstahl im Internet — NICHT.
Tatsächlich sind es doch die Verkäufer geistiger Leistungen, deren Geschäftsmodell darauf beruhte, dass sie Mittelsmänner und Wächter der Verteilungs- und Vervielfältigungstechnologien waren, die durch den freien Zugang zu Informationen bedroht sind.
Was Ihr Verweis auf Sozialismus soll, erschließt sich mir nicht. Falls es ein Totschlagargument sein soll, muss ich Sie enttäuschen — hier darf man, anders als im öffentlichen politischen Diskurs, Sozialist, Kommunist, Kapitalist, Nudist, Sexist, Pazifist, Sado-Masochist und sogar Religionist sein und das auch sagen, ohne dass alle in eine begriffliche Ansgststarre verfallen.
Schutz des …
Interessanterweise war die Phrase 1900 mit Artikel schonmal genauso häufig wie heute ohne:
http://ngrams.googlelabs.com/…=8&smoothing=3
(Und dann nochmal kurz vor 1950.)